Amazon EC2 is the cornerstone for any Amazon-based cloud deployment. Enabling you to provision and scale compute resources with different memory, CPU, networking and storage capacity in multiple regions all around the world, EC2 is by far Amazon’s most popular and widely used service.
Monitoring EC2 is crucial for making sure your instances are available and performing as expected. Metrics such as CPU utilization, disk I/O, and network utilization, for example, should be closely tracked to establish a baseline and identify when there is a performance problem.
Conveniently, these monitoring metrics, together with other metric types, are automatically shipped to Amazon CloudWatch for analysis. While it is possible to use the AWS CLI, API or event the CloudWatch Console to view these metrics, for deeper analysis and more effective monitoring, a more robust monitoring solution is required.
In this article, I’d like to show how to ship EC2 metrics into the ELK Stack and Logz.io. The method I’m going to use is a new AWS module made available in Metricbeat version 7 (beta). While still under development, and as shown below, this module provides an extremely simple way for centrally collecting performance metrics from all your EC2 instances.
Prerequisites
I assume you already have either your own ELK Stack deployed or a Logz.io account. For more information on installing the ELK Stack, check out our ELK guide. To use the Logz.io community edition, click here.
Step 1: Creating an IAM policy
First, you need to create an IAM policy for pulling metrics from CloudWatch and listing EC2 instances. Once created, we will attach this policy to the IAM user we are using.
In the IAM Console, go to Policies, hit the Create policy button, and use the visual editor to add the following permissions to the policy:
- ec2:DescribeRegions
- ec2:DescribeInstances
- cloudwatch:GetMetricData
The resulting JSON for the policy should look like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ec2:DescribeInstances",
"cloudwatch:GetMetricData",
"ec2:DescribeRegions"
],
"Resource": "*"
}
]
}Once saved, attach the policy to your IAM user.
Step 2: Installing Metricbeat
Metricbeat can be downloaded and installed using a variety of different methods, but I will be using Apt to install it from Elastic’s repositories.
First, you need to add Elastic’s signing key so that the downloaded package can be verified (skip this step if you’ve already installed packages from Elastic):
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
The next step is to add the repository definition to your system. Please note that I’m using the 7.0 beta repository since the AWS module is bundled with this version only for now:
echo "deb https://artifacts.elastic.co/packages/7.x-prerelease/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x-prerelease.list
All that’s left to do is to update your repositories and install Metricbeat:
sudo apt-get update && sudo apt-get install metricbeat
Step 3: Configuring Metricbeat
Before we run Metricbeat, there are a few configurations we need to apply.
First, we need to disable the system module that is enabled by default. Otherwise, we will be seeing system metrics in Kibana collected from our host. This is not mandatory but is recommended if you want to keep a cleaner Kibana workspace.
sudo metricbeat modules disable system
Verify with:
ls /etc/metricbeat/module.d envoyproxy.yml.disabled kvm.yml.disabled postgresql.yml.disabled aerospike.yml.disabled etcd.yml.disabled logstash.yml.disabled prometheus.yml.disabled apache.yml.disabled golang.yml.disabled memcached.yml.disabled rabbitmq.yml.disabled aws.yml.disabled graphite.yml.disabled mongodb.yml.disabled redis.yml.disabled ceph.yml.disabled haproxy.yml.disabled mssql.yml.disabled system.yml.disabled couchbase.yml.disabled http.yml.disabled munin.yml.disabled traefik.yml.disabled couchdb.yml.disabled jolokia.yml.disabled mysql.yml.disabled uwsgi.yml.disabled docker.yml.disabled kafka.yml.disabled nats.yml.disabled vsphere.yml.disabled dropwizard.yml.disabled kibana.yml.disabled nginx.yml.disabled windows.yml.disabled elasticsearch.yml.disabled kubernetes.yml.disabled php_fpm.yml.disabled zookeeper.yml.disabled
The next step is to configure the AWS module.
sudo vim /etc/metricbeat/module.d/aws.yml.disabled
Add your AWS IAM user credentials to the module configuration as follows:
- module: aws
period: 300s
metricsets:
- "ec2"
access_key_id: 'YourAWSAccessKey'
secret_access_key: 'YourAWSSecretAccessKey'
default_region: 'us-east-1'In this example, we’re defining the user credentials directly but you can also refer to them as env variables if you have defined as such. There is also an option to use temporary credentials, and in that case you will need to add a line for the session token. Read more about these options in the documentation for the module.
The period setting defines the interval at which metrics are pulled from CloudWatch.
To enable the module, use:
sudo metricbeat modules enable aws
Shipping to ELK
To ship the EC2 metrics to your ELK Stack, simply start Metricbeat (the default Metricbeat configuration has a locally Elasticsearch instance defined as the output so if you’re shipping to a remote Elasticsearch cluster, be sure to tweak the output section before starting Metricbeat):
sudo service metricbeat start
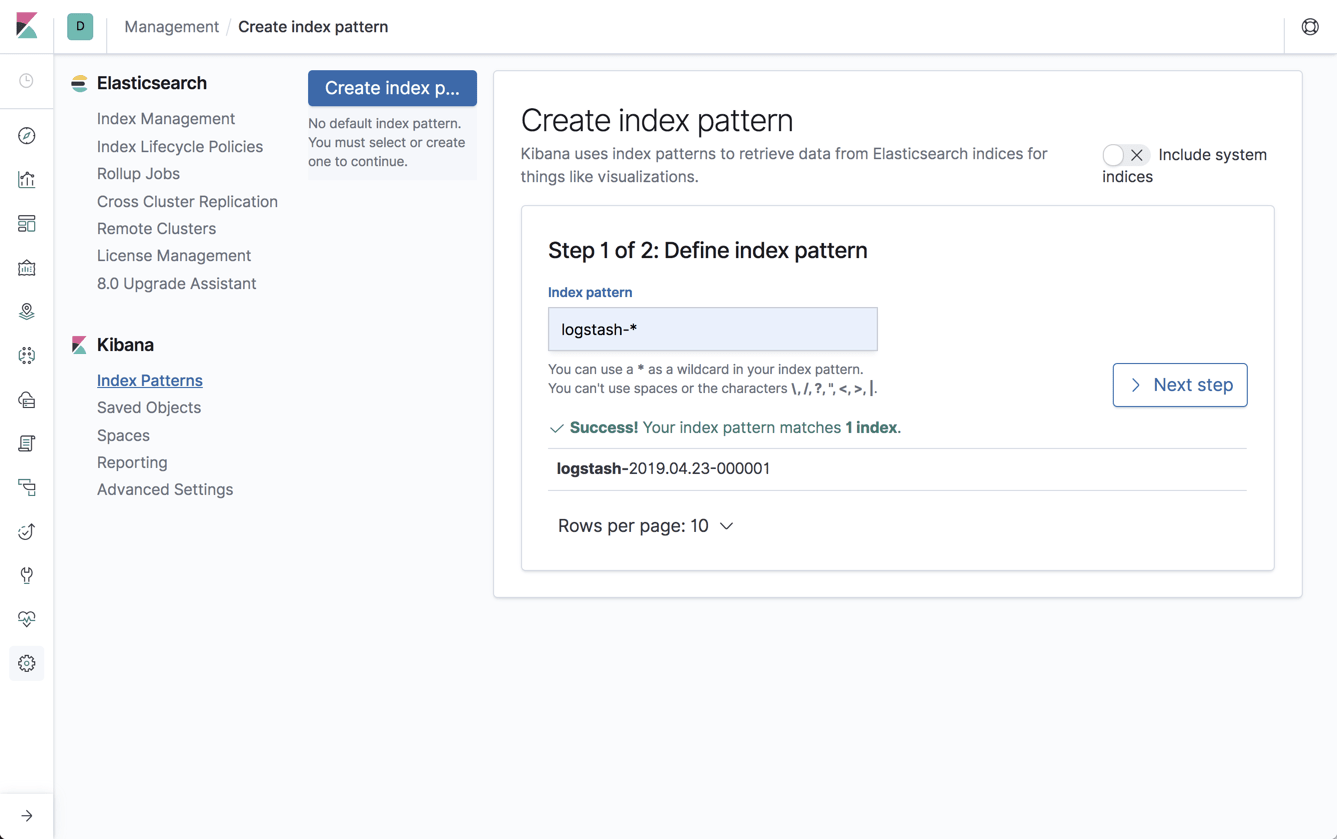
Within a few seconds, you should see a new metricbeat-* index created in Elasticsearch:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .kibana_1 kzb_TxvjRqyhtwY8Qxq43A 1 0 490 2 512.8kb 512.8kb green open .kibana_task_manager ogV-kT8qSk-HxkBN5DBWrA 1 0 2 0 30.7kb 30.7kb yellow open metricbeat-7.0.0-beta1-2019.03.20-000001 De3Ewlq1RkmXjetw7o6xPA 1 1 2372 0 2mb 2mb
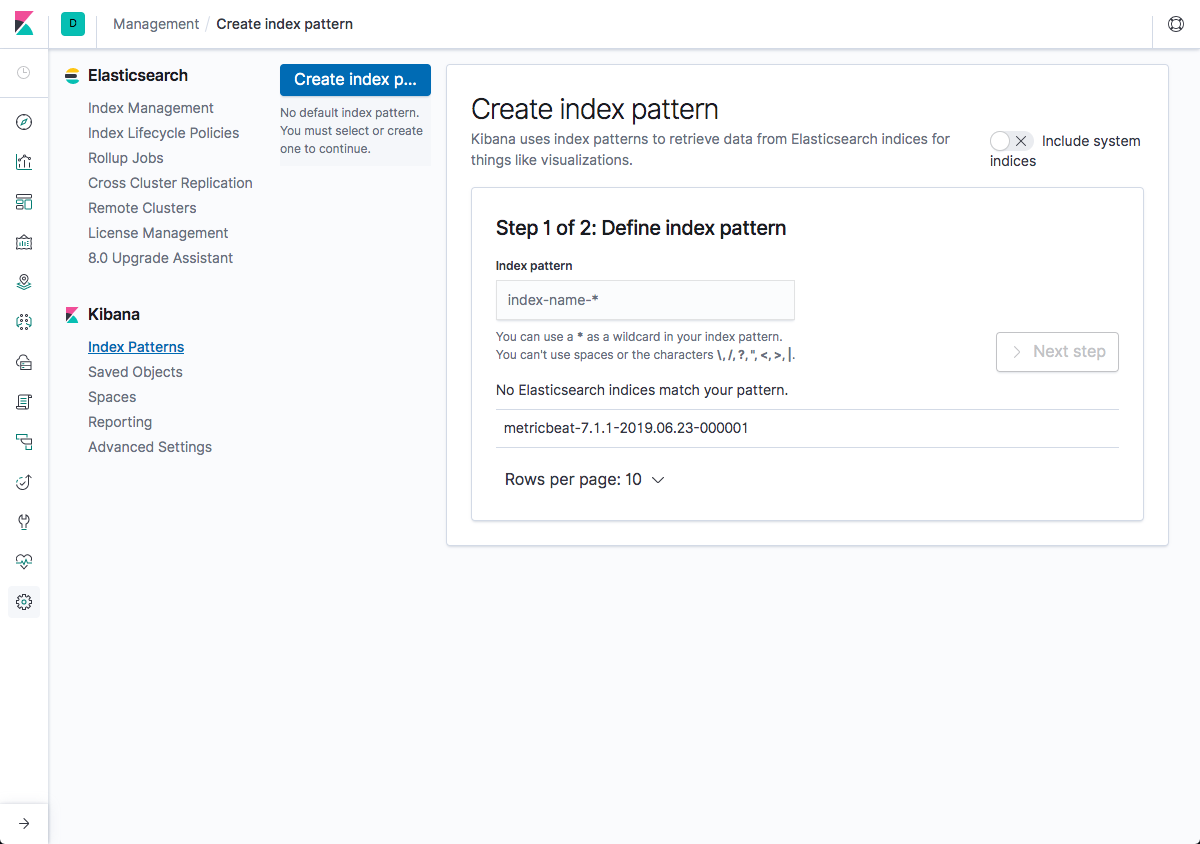
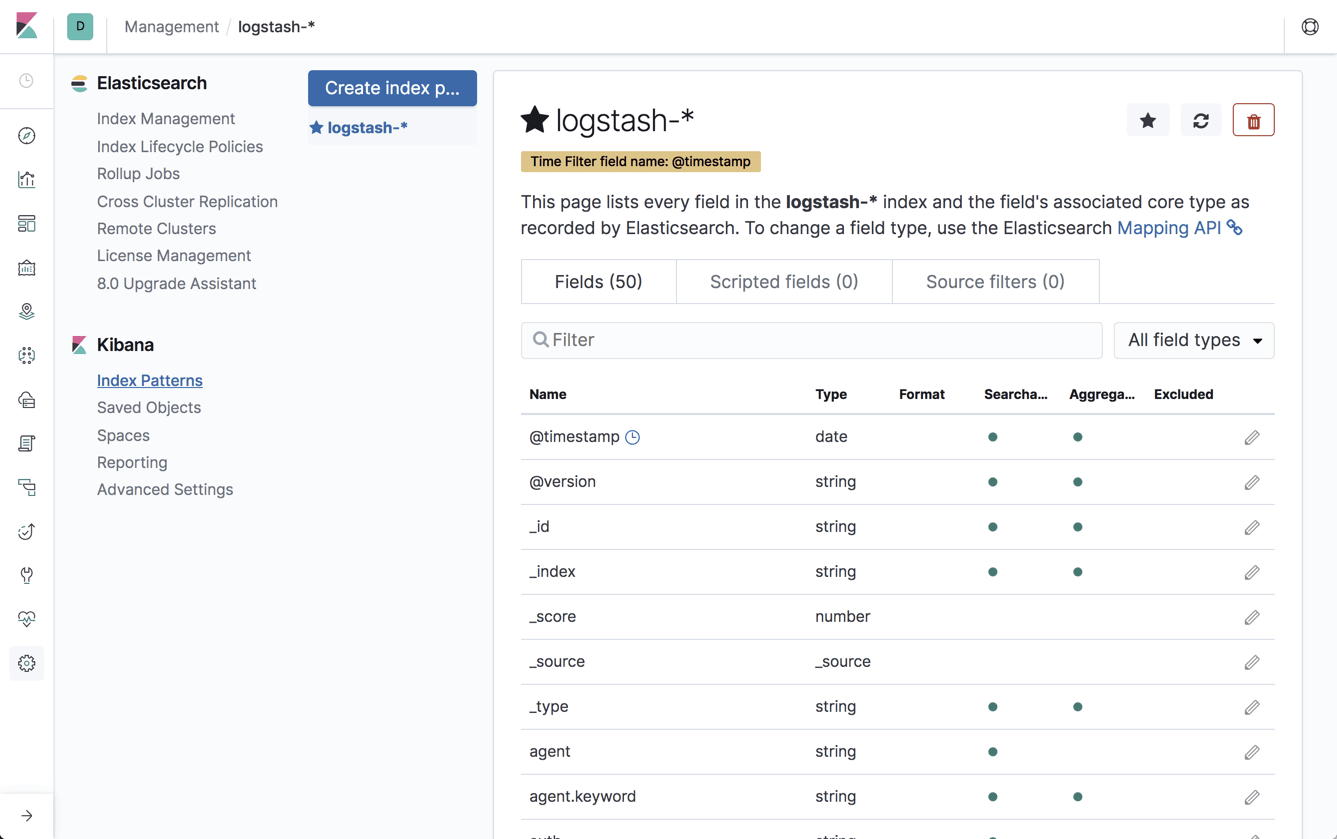
Open Kibana, define the new index patten under Management → Kibana Index Patterns, and you will begin to see the metrics collected by Metricbeat on the Discover page:

Shipping to Logz.io
By making a few adjustments to the Metricbeat configuration file, you can ship the EC2 metrics to Logz.io for analysis and visualization.
First, you will need to download an SSL certificate to use encryption:
wget https://raw.githubusercontent.com/logzio/public-certificates/ master/COMODORSADomainValidationSecureServerCA.crt sudo mkdir -p /etc/pki/tls/certs sudo cp COMODORSADomainValidationSecureServerCA.crt /etc/pki/tls/certs/
Next, retrieve your Logz.io account token from the UI (under Settings → General).
Finally, tweak your Metricbeat configuration file as follows:
fields: logzio_codec: json token: <yourToken> fields_under_root: true ignore_older: 3hr type: system_metrics output.logstash: hosts: ["listener.logz.io:5015"] ssl.certificate_authorities: ['/etc/pki/tls/certs/COMODORSADomainValidationSecureServerCA.crt']
Be sure to enter your account token in the relevant placeholder above and to comment out the Elasticsearch output.
Restart Metricbeat with:
sudo service metricbeat restart
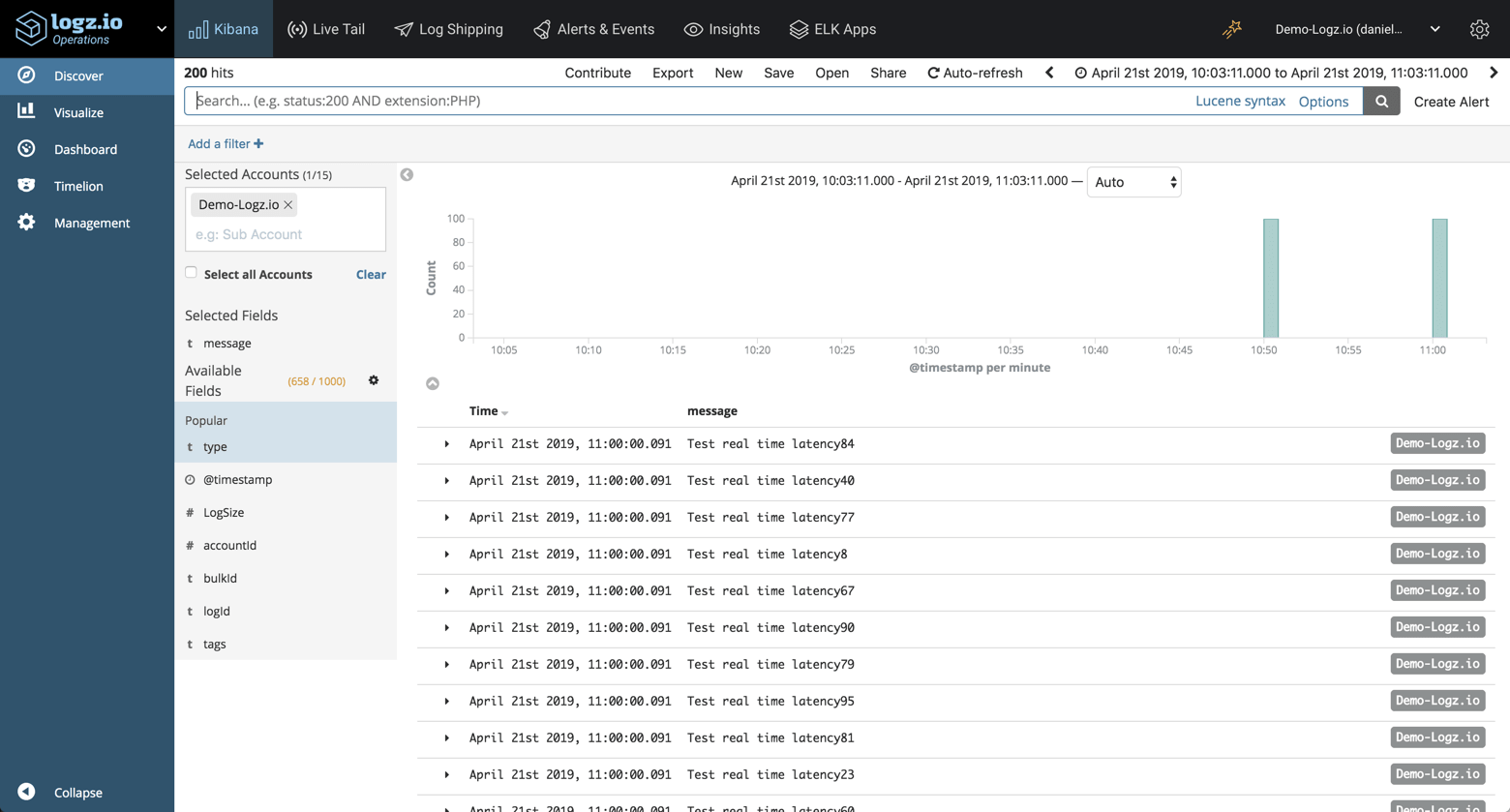
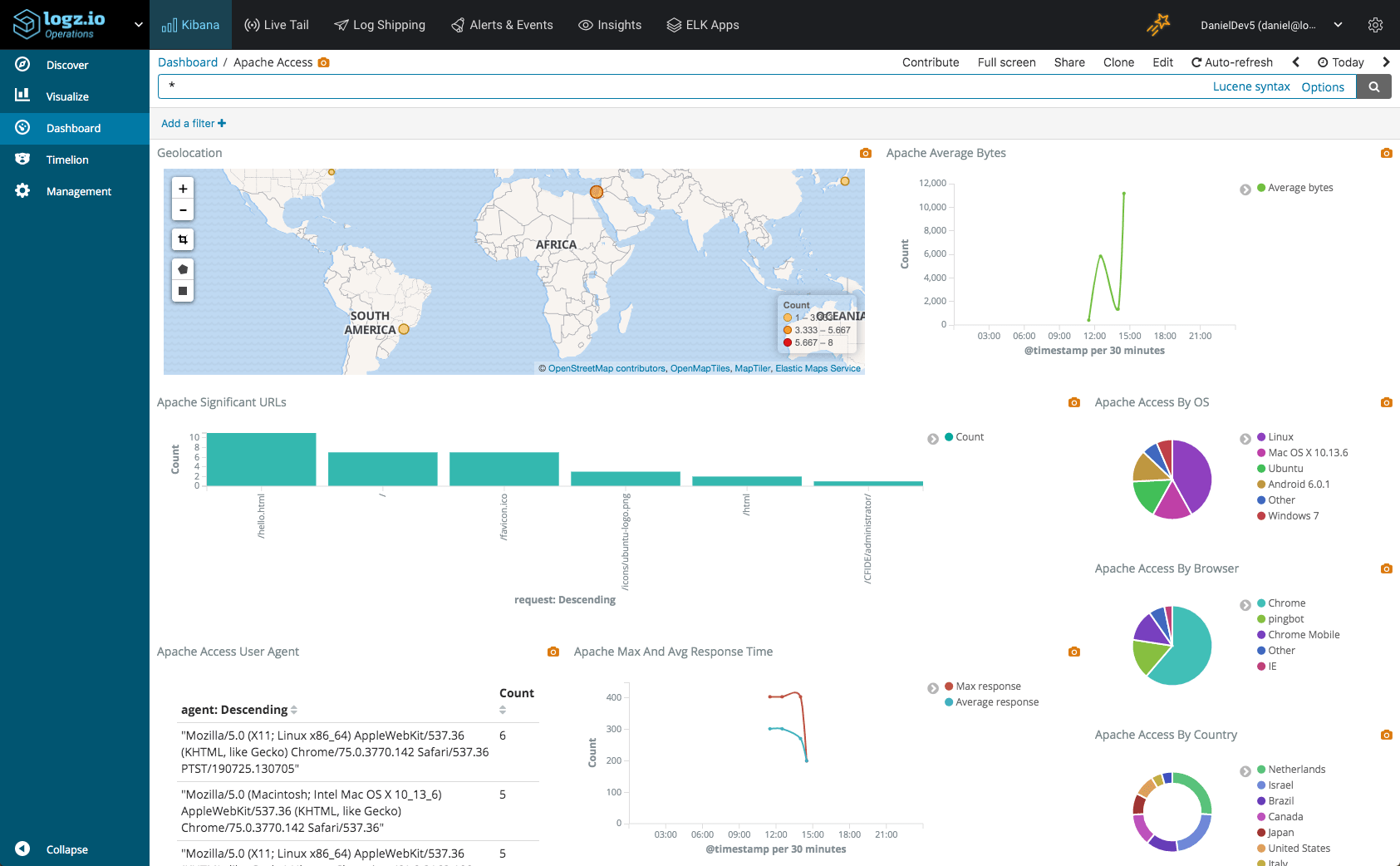
Within a minute or two, you will see the EC2 metrics collected by Metricbeat show up in Logz.io:

Step 4: Analyzing EC2 metrics in Kibana
Once you’ve built a pipeline of EC2 metrics streaming into your ELK Stack, it’s time to reap the benefits. Kibana offers rich visualization capabilities that allow you to slice and dice data in any way you want. Below are a few examples of how you can start monitoring your EC2 instances with visualizations.
Failed status checks
CloudWatch performs different types of status checks for your EC2 instances. Metrics for these checks can be monitored to keep tabs on the availability and status of your instances. For example, we can create a simple metric visualization to give us an indication on whether any of these checks failed:

CPU utilization
Kibana’s visual builder visualization is a great tool for monitoring time series data and is improving from version to version. The example below gives us an average aggregation of the ‘aws.ec2.cpu.total.pct’ field per instance.

Network utilization
In the example below, we’re using the visual builder again to look at an average aggregation of the ‘aws.ec2.network.in.bytes’ field per instance to monitor incoming traffic. In the Panel Options tab, I’ve set the interval at ‘5m’ to correspond with the interval at which we’re collecting the metrics from CloudWatch.

We can do the same of course for outgoing network traffic:

Disk performance
In the example here, we’re monitoring disk performance of our EC2 instances. We’re showing an average of the ‘aws.ec2.diskio.read.bytes’ and the ‘aws.ec2.diskio.write.bytes’ fields, per instance:


Summing it up
The combination of CloudWatch and the ELK Stack is a great solution for monitoring your EC2 instances. Previously, Metricbeat would have been required to be installed per EC2 instance. The new AWS module negates this requirement, making the process of shipping EC2 metrics into either your own ELK or Logz.io super-simple.
Once in the ELK Stack, you can analyze these metrics to your heart’s delight, using the full power of Kibana to slice and dice the metrics and build your perfect EC2 monitoring dashboard!

This dashboard is available in ELK Apps — Logz.io’s library of premade dashboards and visualizations for different log types. To install, simply open ELK Apps and search for ‘EC2’.
Looking forward, I expect more and more metricsets being supported by this AWS module, meaning additional AWS services will be able to be monitored with Metricbeat. Stay tuned for news on these changes in this blog!