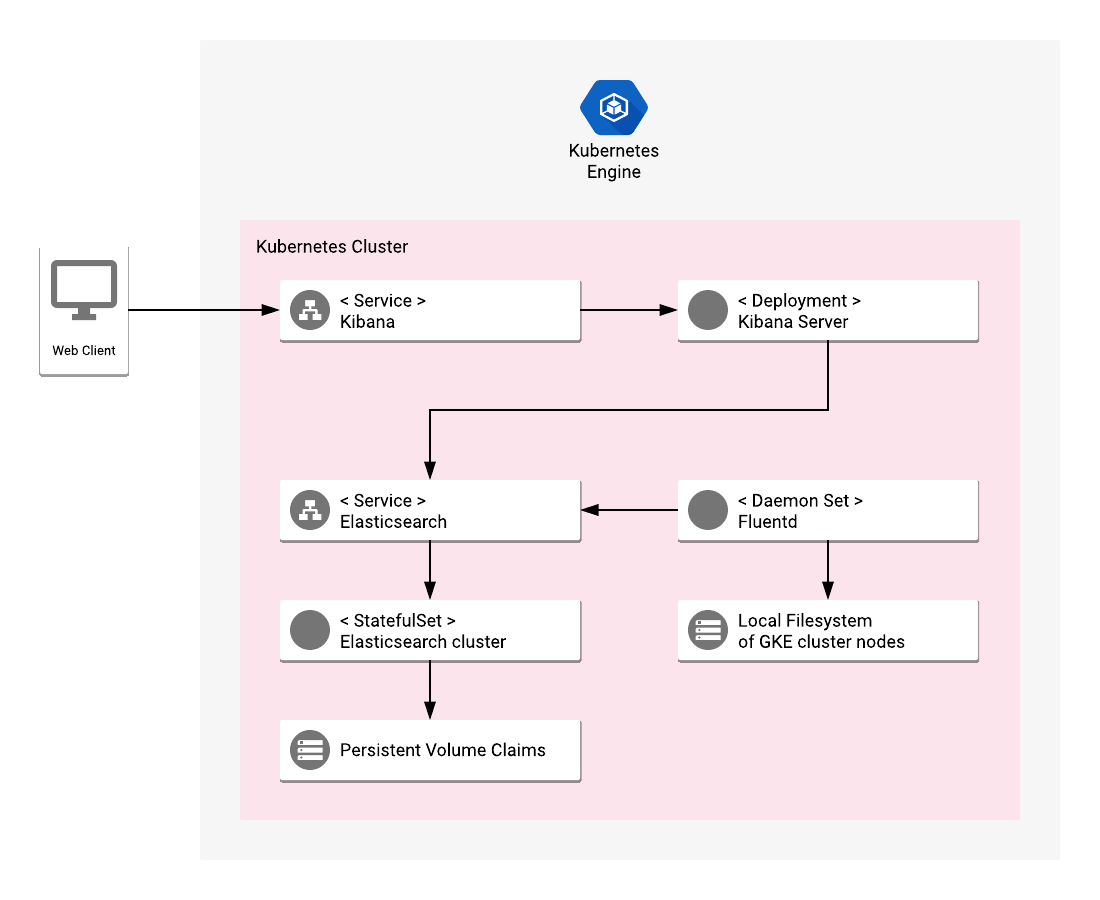
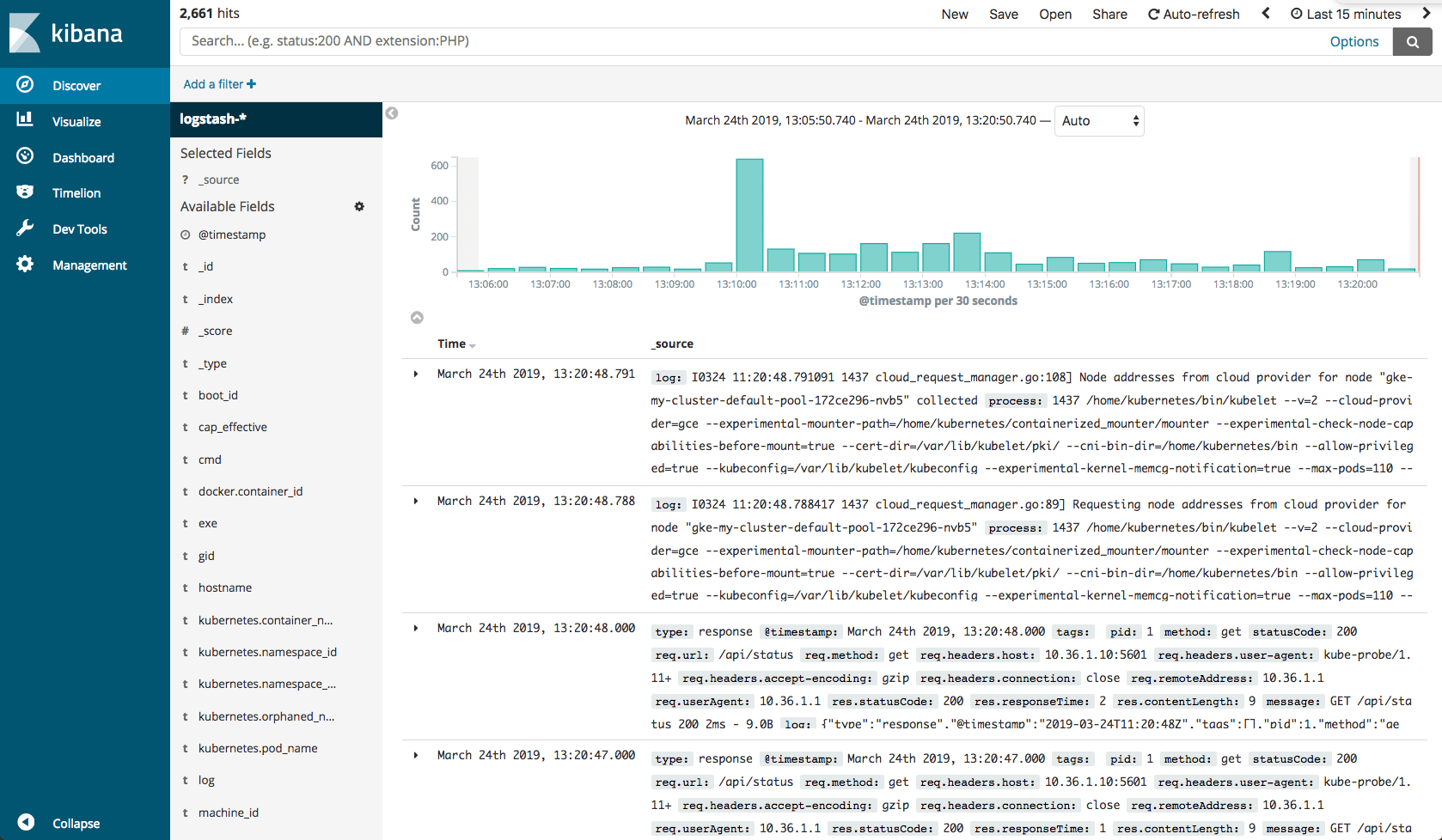
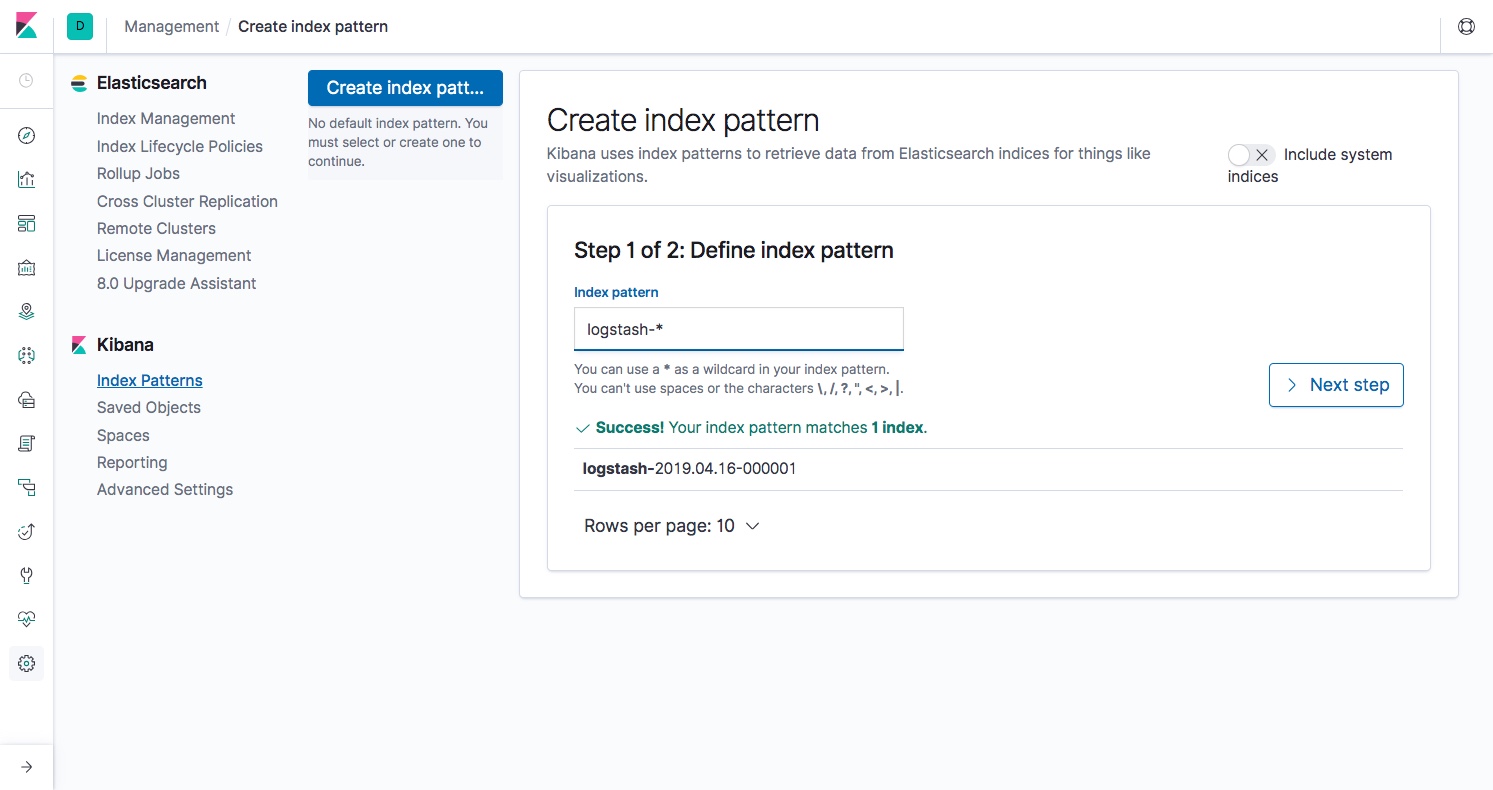
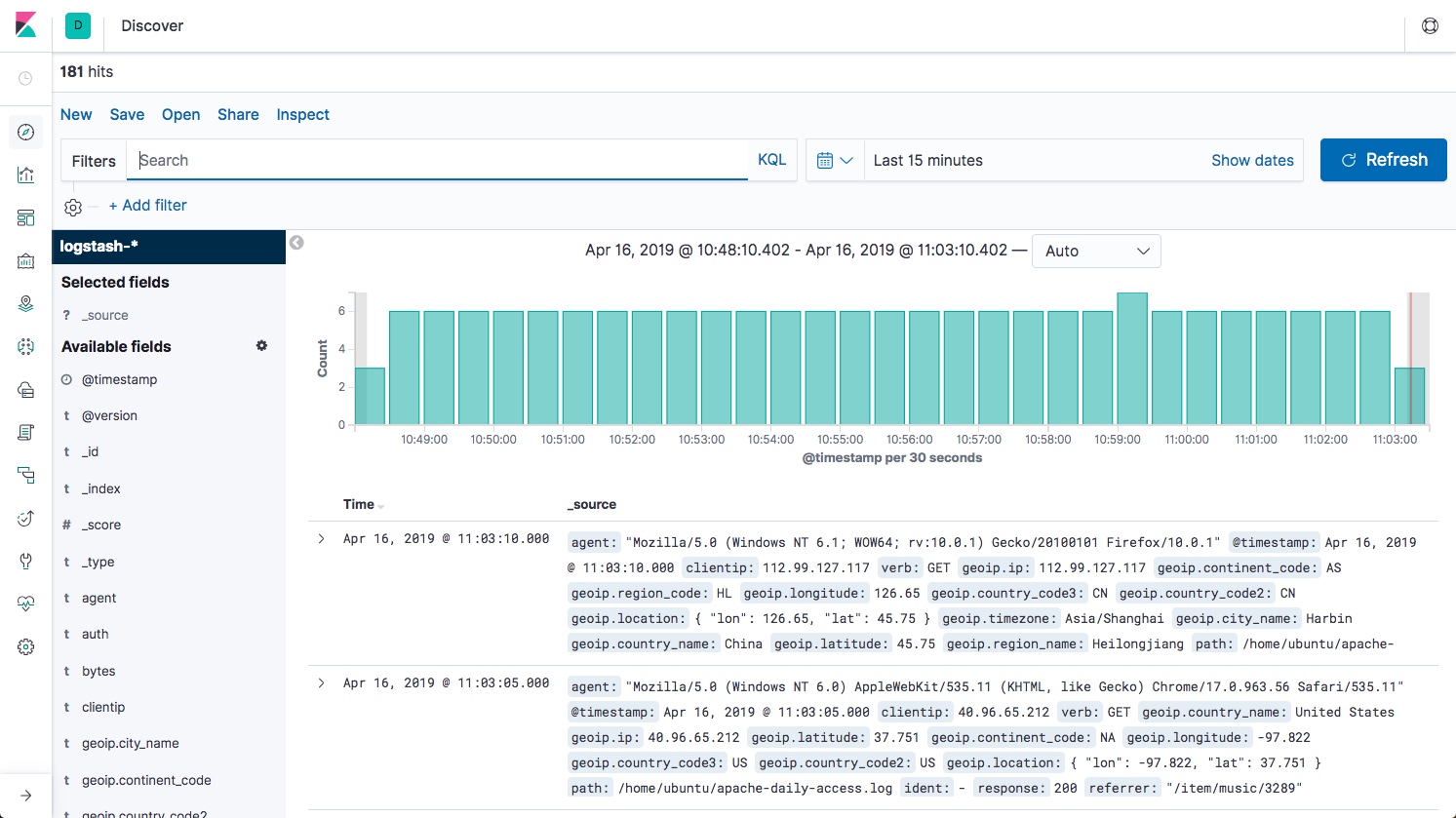
SIEM has been with us for almost two decades now and is seen as a proven approach to dealing with potential threats as well as actual attacks on business critical systems. But today, it is becoming clear that changes in IT infrastructure and deployment practices are giving rise to new challenges that cannot be met by existing SIEM platforms.
In this article, we take a look at legacy SIEM systems and examine their limitations. Next, we talk about Security Analytics-based, next-generation SIEM products and what they offer. We conclude the article by examining the benefits of replacing older legacy systems with next-generation SIEM platforms.
Legacy SIEM and Its Limitations
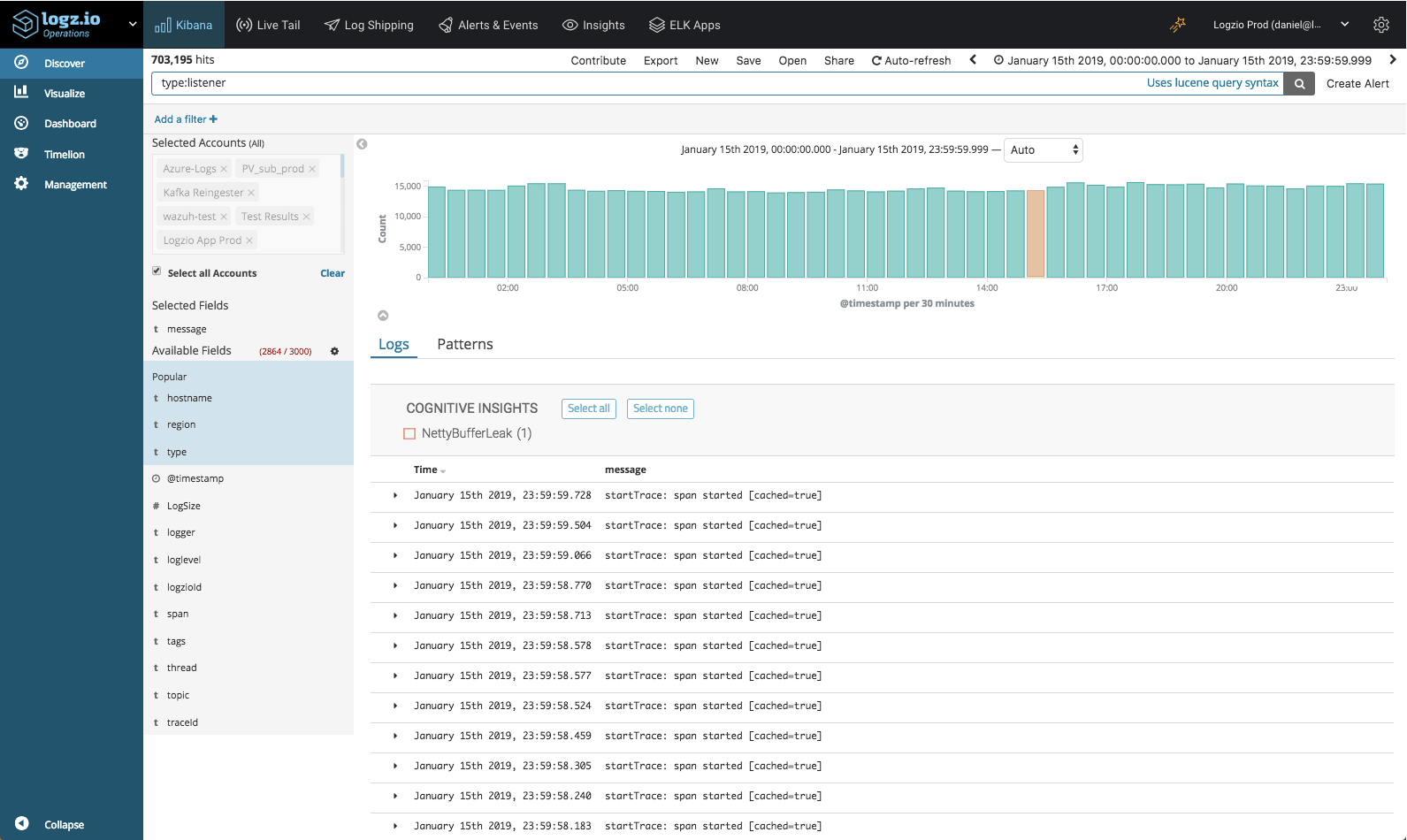
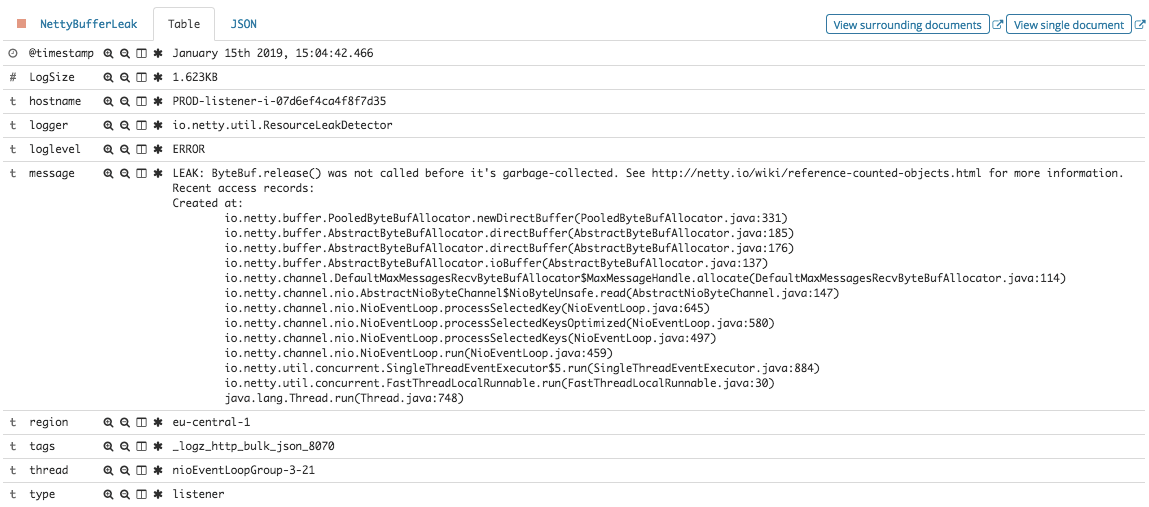
Security information and event management (SIEM) systems collect log data generated by monitored devices (computers, network equipment, storage, firewalls, etc.) to both identify specific security-related events that occur on individual machines and aggregate this information to see what is happening across an entire system. The purpose of these activities is to identify any deviations from expected behavior and to be able to formulate and implement the appropriate response. To this end, SIEM products offer a range of functionalities that include log collection, event detection, system monitoring, behavior analysis, compliance management, threat hunting, and centralized reporting services.
Costs
In recent years, the limitations of the current generation of SIEM products have become increasingly apparent. For a start, current SIEM solutions may not seem very expensive on the surface. But when you take into account the costs of the related hardware, software, and personnel required, you can end up paying between $100,000 to $500,000 per annum, or even higher.
One hidden cost of deploying SIEM is time. After all, if you are going to the trouble of building a system that is designed to help protect your organization’s equipment and data, you want to get it right. Moreover, in order to fulfill its intended purpose, you must integrate your SIEM system with your current infrastructure, and this definitely takes time. Therefore, it is no surprise that even the simplest SIEM deployment can take a minimum of six months, and more complex systems will take much longer.
Why & When Were They Built?
Legacy SIEM systems were designed to combat a large range of potential threats. The systems were implemented using a one-size fits all approach that created tightly coupled, monolithic applications that are hard to update. These systems also used available data storage technologies to persist system logs and related information, such as relational databases or proprietary file formats. Unfortunately, such storage technologies favor a highly structured approach to data management that is highly inflexible and very difficult to update and/or change.
In addition, these products were designed well before the rise of large cloud providers and solid-state drive technologies. As a result, they utilized an organization’s on-premise infrastructure and relied on existing spinning (hard) disk technologies. This led to systems that were unable to store the vast quantities of collected log data, let alone provide the performance required to analyze it. Due to these design limitations, legacy SIEM systems are simply not built to handle modern CI/CD lifecycles—based on frequent build and deployment cycles—and cannot handle the vast amounts of data generated by these methods.
Deeper Issues of Legacy SIEM
From what we have described, you might be tempted to think that the problems of legacy SIEM can simply be fixed via buying new hardware. But there are a number of deeper issues with SIEM software. Many SIEM systems identify deviant behavior using a rules-based approach. Each time the system detects a threat, it tries to match it against a collection of defined behavior patterns based on previously detected incidents. But a major problem for this rules-based approach to SIEM is that it that can only handle problems that have been caught and cataloged. It is unable to provide answers to any new attacks and exploits. This approach also works better at dealing with local incidents rather than system-wide attacks.
Some SIEM systems overcome these issues by using a statistical approach that correlates logged events across an entire system and determines relationships between them that could indicate an attack. The downside of this approach is that it can generate a high number of false positive results. Unfortunately, at the end of the day, both approaches were designed to handle only external threats. This means that no matter which method you use, neither offers a solution for problems already behind the corporate firewall and thus cannot protect against them.
Security Analytics and Next-Generation SIEM
One of the key problems with current SIEM approaches is that it forces you to take a reactive and passive approach to security. In contrast, Security Analytics takes a long-term approach to system and data security. To understand the difference between these two, let’s take a look at what is meant by Security Analytics and how it differs from SIEM.
What Is Security Analytics
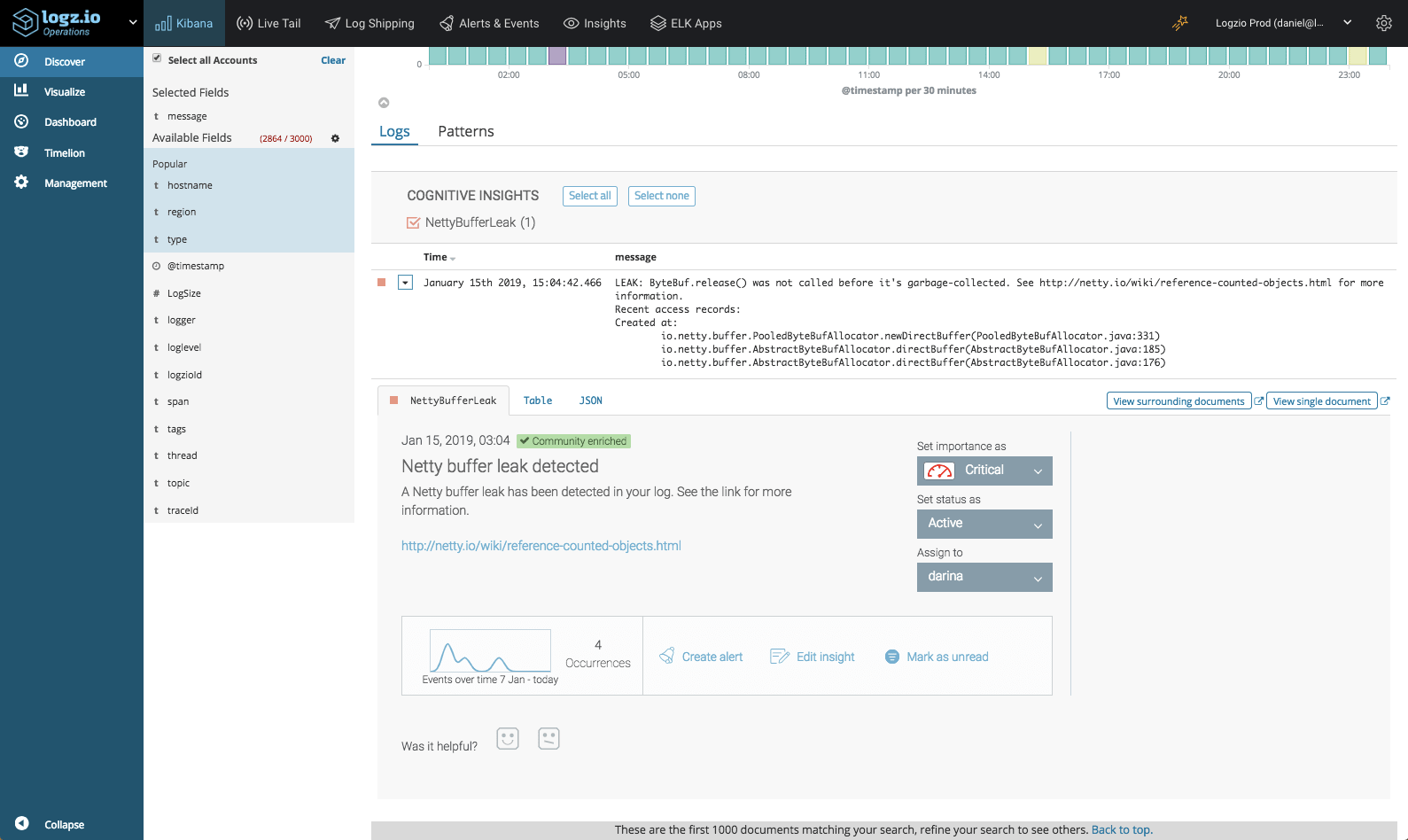
Security Analytics focuses on the analysis of data to produce proactive security measures. This results in a flexible approach that can be constantly improved to handle new threats and vectors. As its name suggests, Security Analytics emphasizes the analysis of security data instead of managing it. In order to provide effective analysis, Security Analytics tools collect data from numerous sources, including external and internal network traffic, access and identity management systems, connected devices, and business software. This data is then combined with external security threat intelligence and existing collections of reported security incidents.
The collected data is processed and analyzed using traditional statistical analysis and augmented with artificial intelligence and machine learning. As a result, you can gauge potential threats based on what is happening both inside your system and in the world outside your corporate network. Not only can this approach handle known and understood threats, it can also deal with “we don’t know what we don’t know” scenarios.
Cloud-Based Infrastructure
Unlike legacy SIEM, Security Analytics can take full advantage of cloud-based infrastructure. First of all, cloud storage providers can provide almost unlimited, indefinite data storage that can scale according to your needs. This enables you to keep potentially useful data without being limited by corporate data storage and retention policies.
Not only are next-generation systems better at collecting and storing data, they are better at handling modern DevOps practices and CI/CD systems. These systems build and deploy software at increasing speed and, in the process, generate more data than traditional, on-premise SIEM solutions can handle. Another key advantage of cloud-based systems is that they drastically reduce the time required to deploy and implement. Using a cloud-based SIEM platform, you can deploy an SIEM solution in hours, instead of months or even years.
But Do You Get Better Security?
While lower costs and deployment times makes Security Analytics tools an attractive proposition, what really matters is whether they overcome the limitations of their predecessors and offer better system security.
As we previously noted, legacy SIEM systems were monolithic applications designed to handle external threats to on-premises IT infrastructures. Modern security systems are built around highly distributed systems that include cloud, hybrid cloud, and local elements. Unlike the older platforms, they use an analytical approach that is not limited to a finite range of potential security scenarios and well-known threats. Instead, they use existing security data and pre-packaged threat analysis that can identify new problems as soon as they appear.
In addition, this new approach augments existing statistical-based models with the latest advances in machine intelligence and deep learning. Because of this, the new SIEM systems based on Security Analytics can not only identify known threats, they can learn to identify undocumented problems by analyzing massive amounts of data to uncover hidden relationships, anomalies, trends, and fraudulent behavioral patterns.
Conclusion: The Only Way Is Up
Legacy SIEM systems have been around for a long time. And until recently, they’ve been doing a great job of protecting our IT infrastructure. Still, no matter how well legacy SIEM products have performed in the past, they are beginning to show their age.
Security Analytics is designed to proactively protect your organization’s vital data and infrastructure. These systems are not only less costly and resource hungry than the older systems they replace. They are also a better fit for modern cloud and hybrid cloud-based infrastructures and work with newer DevOps practices. Ultimately, Security Analytics products offer better protection, greater scalability, and reduced costs. In this light, you should be asking yourself if it’s time to migrate to a next-generation solution. Given the evidence, the answer to this question is a resounding “Yes.” And you should do so as soon as possible.