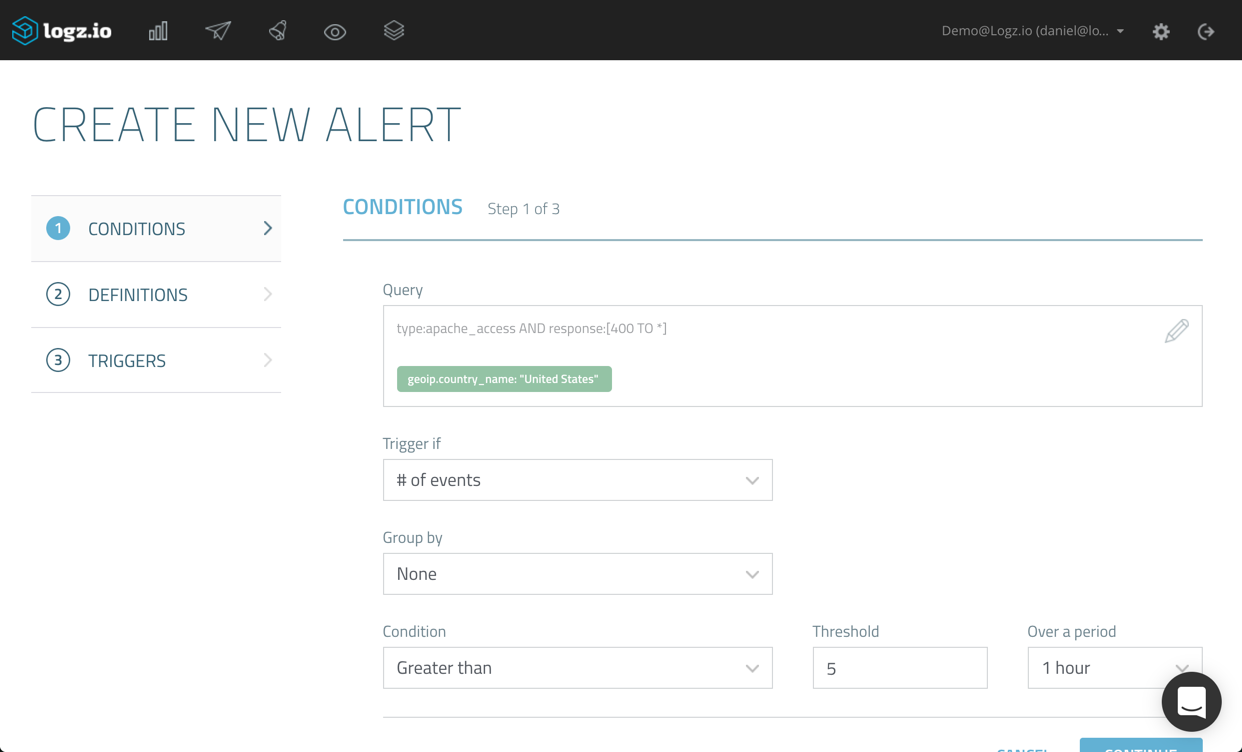
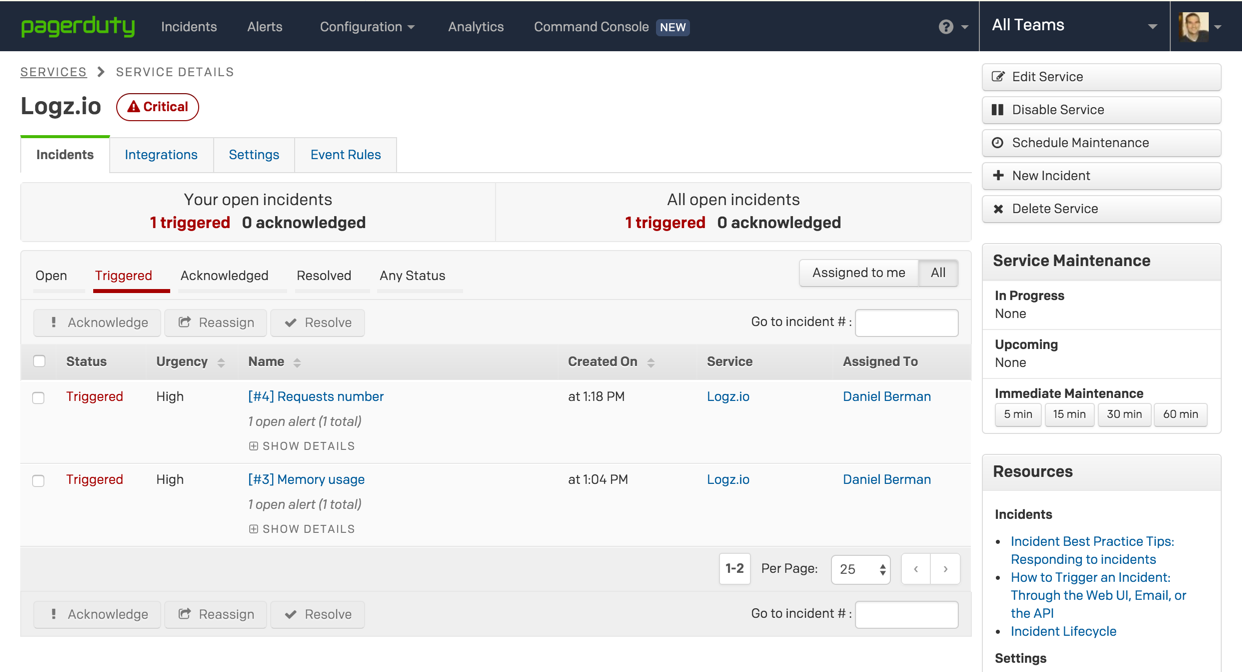
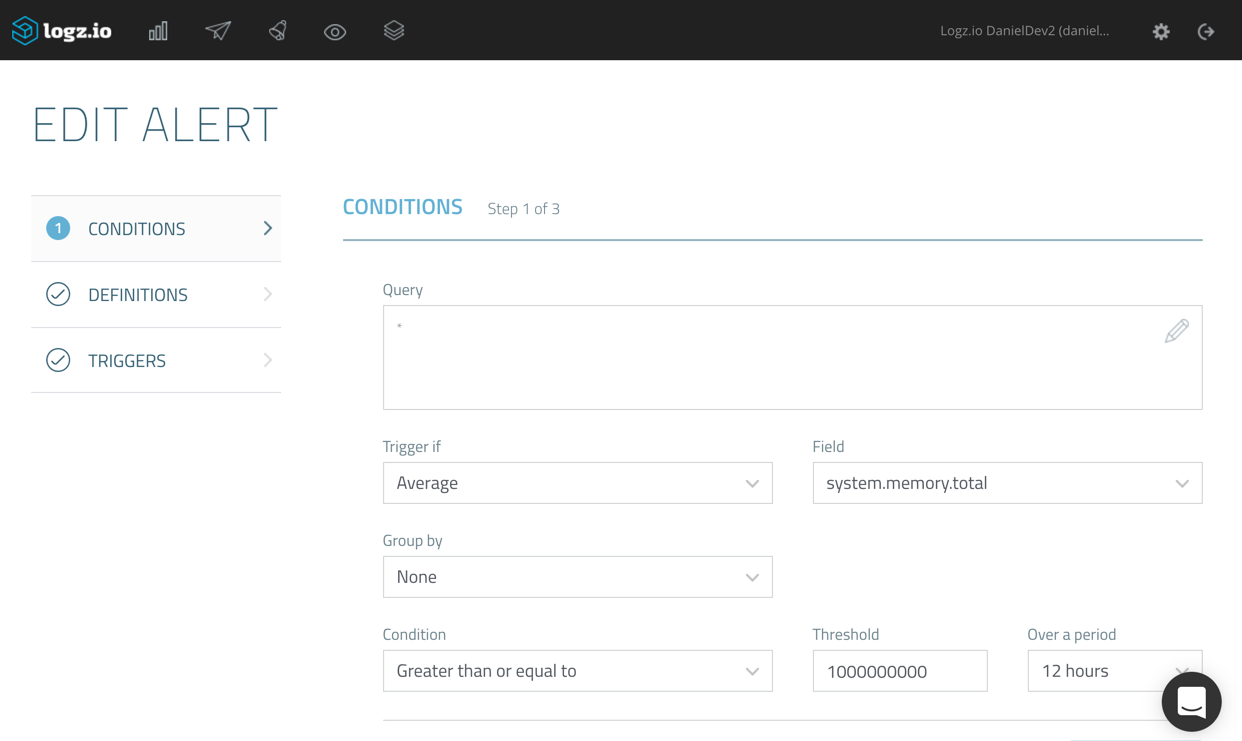
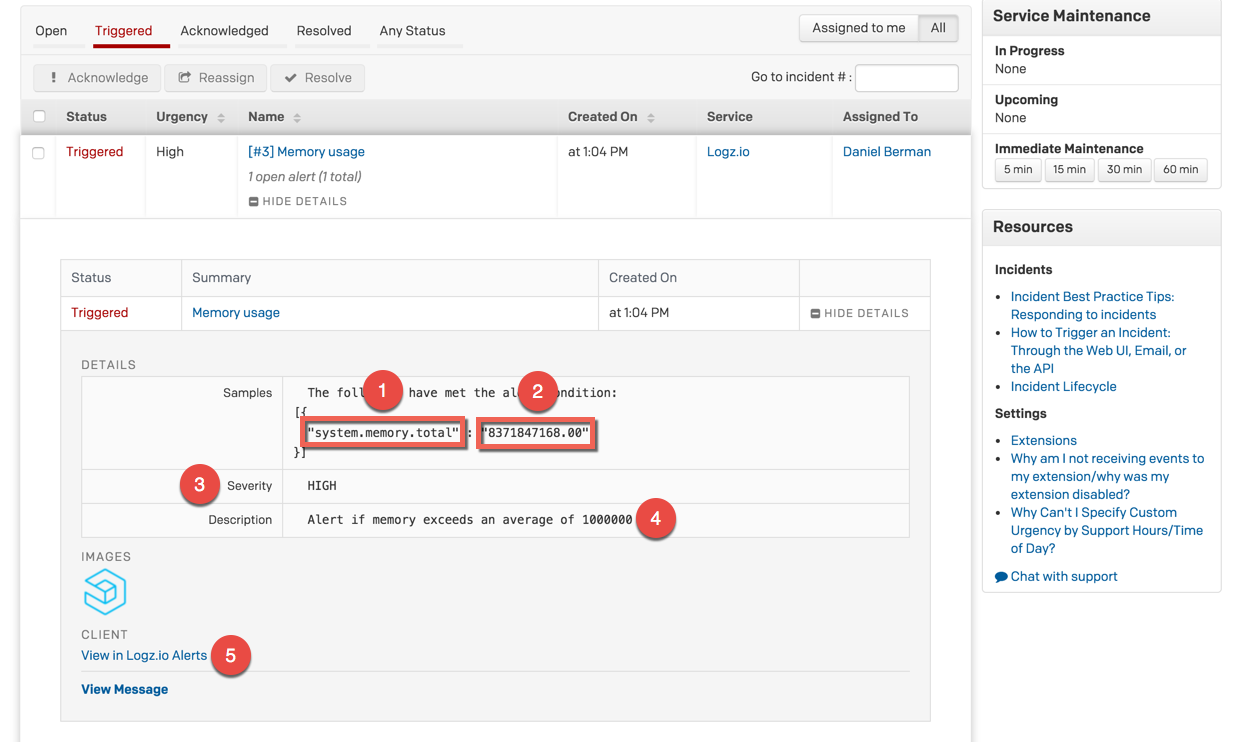
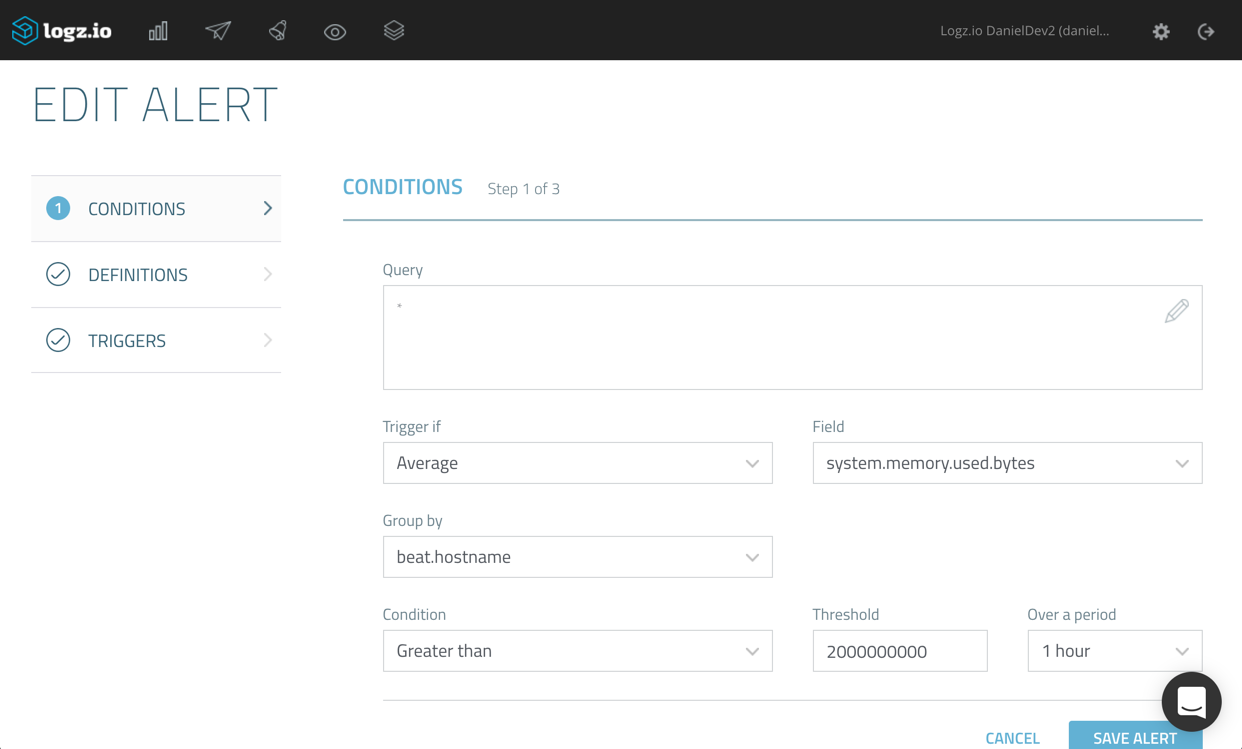
![aws reinvent 2016 sessions]()
Autumn in Las Vegas means one thing — it’s time for AWS re:Invent. One of the largest global technological events in the world and the most important event in the world of cloud computing, re:Invent this year promises to be even bigger than in previous years.
The size of this event can be overwhelming, both physically (be sure to drink a lot of water!) and content-wise. With around 20,000 attendees, eight tracks, and 192 breakout sessions, it’s not easy, to say the least, to find one’s bearings. In addition to the keynotes, product announcements, and sponsor events, there are some excellent breakout sessions for learning about the latest developments in the industry.
But how to choose where to be? Below, I’ve listed the top ten sessions — in no particular order — that we think are worth a ticket to re:Invent in their own right, together with some useful background and practical information to guide you.
Because of the variety on offer, it was extremely difficult to build this list. Being a big data and log analysis company, Logz.io has a natural inclination towards architectural and Big Data sessions, but we also added some “must see” sessions from other fields.
Enjoy!
#1 – From Resilience to Ubiquity – #NetflixEverywhere Global Architecture (ARC204)
Speaker: Coburn Watson, Director of Performance and Reliability, Netflix
Track: Architecture
Level: Introductory
When: Tuesday, Nov 29, 9:30 AM – 10:30 AM
Why we like this session: Netflix has extensive experience in building a fault-resilient and available global service, and the company has not been shy about sharing its engineering goodness with the community. Learning from the Netflix’s war stories and architectural journey promises to be highly illuminating!
Abstract: “Building and evolving a pervasive, global service requires a multi-disciplined approach that balances requirements with service availability, latency, data replication, compute capacity, and efficiency. In this session, we’ll follow the Netflix journey of failure, innovation, and ubiquity. We’ll review the many facets of globalization and then delve deep into the architectural patterns that enable seamless, multi-region traffic management; reliable, fast data propagation; and efficient service infrastructure. The patterns presented will be broadly applicable to internet services with global aspirations.”
#2 – Amazon CloudWatch Logs and AWS Lambda: A Match Made in Heaven (DEV301)
Speaker: Bob Wilkinson, General Manager, AWS CloudWatch
Track: DevOps & Tools
Level: Advanced
When: Thursday, Dec 1, 11:00 AM – 12:00 PM
Why we like this session: The combination between AWS Lambda and CloudWatch in the scenarios included in the session are what peaked our interest. Providing an ELK (Elasticsearch, Logstash and Kibana) solution ourselves, we’re also extremely intrigued to hear about building Elasticsearch clusters on AWS, and using CloudWatch together with Lambda and S3.
Abstract: “In this session, we cover three common scenarios that include Amazon CloudWatch Logs and AWS Lambda. First, you learn how to build an Elasticsearch cluster from historical data using Amazon S3, Lambda, and CloudWatch Logs. Next, you learn how to add details to CloudWatch alarm notifications using Amazon SNS and Lambda. Finally, we show you how to bring Elastic Load Balancing logs to CloudWatch Logs using S3 bucket triggers from Lambda.”
#3- Introduction to Container Management on AWS (CON303)
Speaker: Brandon Chavis, Solutions Architect, AWS
Track: Containers Mini Con
Level: Advanced
When: Thursday, Dec 1, 2:00 PM – 3:00 PM
Why we like this session: It’s the rise of the Container Era! Containers are one of the hottest topics in the world of DevOps. We’re looking forward to hearing about the analysis and comparison between AWS ECS, Docker, Kubernetes, and Mesos.
Abstract: “Managing and scaling hundreds of containers is a challenging task. A container management solution takes care of these challenges for you, allowing you to focus on developing your application. In this session, we cover the role and tasks of a container management solution and we analyze how four common container management solutions — Amazon EC2 Container Service, Docker for AWS, Kubernetes, and Apache Mesos — stack against each other. We also see how you can easily get started with each of these solutions on AWS.”
#4 – Metering Big Data at AWS: From 0 to 100 Million Records in 1 Second (ARC308)
Speaker: Diego Macadar, Software Development Manager, AWS
Track: Architecture
Level: Advanced
When: Wednesday, Nov 30, 2:00 PM – 3:00 PM
Why we like this session: The numbers to be presented in this session are what attracted our attention. Learning how AWS maintains its huge processing pipeline while dealing with scaling and accuracy promises to be extremely educational.
Abstract: “Learn how AWS processes millions of records per second to support accurate metering across AWS and our customers. This session shows how we migrated from traditional frameworks to AWS managed services to support a large processing pipeline. You will gain insights on how we used AWS services to build a reliable, scalable, and fast processing system using Amazon Kinesis, Amazon S3, and Amazon EMR. Along the way we dive deep into use cases that deal with scaling and accuracy constraints. Attend this session to see AWS’s end-to-end solution that supports metering at AWS.”
#5- Securing Container-Based Applications (CON402)
Speakers:
Michael Capicotto, Solutions Architect, AWS
Henrik Johansson, Security Solutions Architect, AWS
Track: Containers Mini Con
Level: Expert
When: Thursday, Dec 1, 12:30 PM – 1:30 PM
Why we like this session: Security and Docker — two words that are not uttered lightly. There is plenty of debate in the community on whether Docker is ready for the enterprise world, and security is often used as the reason why it is not. It’ll be interesting to hear how AWS helps with the security concerns.
Abstract: “Containers have had an incredibly large adoption rate since Docker was launched, especially from the developer community, as it provides an easy way to package, ship, and run applications. Securing your container-based application is now becoming a critical issue as applications move from development into production. In this session, you learn ways to implement storing secrets, distributing AWS privileges using IAM roles, protecting your container-based applications with vulnerability scans of container images, and incorporating automated checks into your continuous delivery workflow.”
#6 – Evolving a Responsive and Resilient Architecture to Analyze Billions of Metrics (ARC311)
Speakers:
Jim Tran, Enterprise SA, AWS
Thomas Lockney, Engineering Manager, Nike
Owyn Richen, Sr. Director Platform Delivery, Nike
Track: Architecture
Level: Advanced
When: Thursday, Dec 1, 5:30 PM – 6:30 PM
Why we like this session: Nike and Big Data, need I say more? Even if you are more of an Adidas type of guy or gal, this session promises plenty of valuable tips on building a stable, flexible, and robust architecture that can successfully handle billions of metrics a day.
Abstract: “Nike+ is at the core of the Nike digital product ecosystem, providing services to enhance your athletic experience through quantified activity tracking and gamification. As one of the first movers at Nike to migrate out of the datacenter to AWS, they share the evolution in building a reactive platform on AWS to handle large, complex data sets. They provide a deep technical view of how they process billions of metrics a day in their quantified-self platform, supporting millions of customers worldwide. You’ll leave with ideas and tools to help your organization scale in the cloud. Come learn from experts who have built an elastic platform using Java, Scala, and Akka, leveraging the power of many AWS technologies like Amazon EC2, ElastiCache, Amazon SQS, Amazon SNS, DynamoDB, Amazon ES, Lambda, Amazon S3, and a few others that helped them (and can help you) get there quickly.”
#7 – Architecting Next Generation SaaS Applications on AWS (ARC301)
Speaker: Tod Golding, Partner Solutions Architect, AWS
Track: Architecture
Level: Advanced
When: Wednesday, Nov 30, 11:30 AM – 12:30 PM
Why we like this session (and the next one as well): As a company that has built its SaaS product on AWS, we highly recommend this session for companies either currently in the process of planning their SaaS platform or those working on existing SaaS applications deployed on AWS.
We will definitely be there!
Abstract: “AWS provides a broad array of services, tools, and constructs that can be used to design, operate, and deliver SaaS applications. In this session, Tod Golding, the AWS Partner Solutions Architect, shares the wisdom and lessons learned from working with dozens of customers and partners building SaaS solutions on AWS. We discuss key architectural strategies and patterns that are used to deliver multi-tenant SaaS models on AWS and dive into the full spectrum of SaaS design and architecture considerations, including tenant isolation models, tenant identity management, serverless SaaS, and multi-tenant storage strategies. This session connects the dots between general SaaS best practices and what it means to realize these patterns on AWS, weighing the architectural tradeoffs of each model and assessing its influence on the agility, manageability, and cost profile of your SaaS solution.”
#8 – Optimizing SaaS Solutions on AWS (ARC408)
Speaker: Tod Golding, Partner Solutions Architect, AWS
Track: Architecture
Level: Expert
When: Thursday, Dec 1, 2:00 PM – 3:00 PM
Why we like this session: The same as above, but this is bit more advanced, with more detailed and technical information on dealing with performance optimization strategies.
Abstract: “OK, so you have your SaaS application up and running on AWS and now the real fun begins. The adoption of SaaS and a shared multi-tenant infrastructure brings with it a unique set of challenges that require developers to find new and creative ways to optimize their SaaS applications. For many engineers, this means tackling a whole new realm of questions. How do you optimize tenant experience by tiers? How do you perform real-time performance tuning or centralized tenant policy management? How do you collect and aggregate tenant analytics? How do you implement scalable policy-driven configuration of tenant experience? These and many other challenging topics will be covered in this technical deep dive. Tod Golding, an AWS Solutions Architect specializing in helping AWS partners build SaaS systems, will explore a collection of strategies that can be leveraged to increase the performance, flexibility, and agility of SaaS environments. You will learn how to identify areas where services, tools, and design strategies can be combined to enrich the agility of your SaaS architecture.”
#9 – Serverless Architectural Patterns and Best Practices (ARC402)
Speakers:
Drew Dennis, Solutions Architect, AWS
Maitreya Ranganath, Solutions Architect, AWS
Ajoy Kumar, Architect, BMC Software
Track: Architecture
Level: Expert
When: Wednesday, Nov 30, 5:00 PM – 6:00 PM
Why we like this session: “Serverless” is all the rage these days, with more and more services and methodologies emerging on a daily basis. To help to understand why “serverless” is becoming so popular, we would like to hear about the different frameworks and patterns used.
Abstract: “As serverless architectures become more popular, AWS customers need a framework of patterns to help them deploy their workloads without managing servers or operating systems. This session introduces and describes four re-usable serverless patterns for web apps, stream processing, batch processing, and automation. For each, we provide a TCO analysis and comparison with its server-based counterpart. We also discuss the considerations and nuances associated with each pattern and have customers share similar experiences. The target audience is architects, system operators, and anyone looking for a better understanding of how serverless architectures can help them save money and improve their agility.”
#10 – Cloud Monitoring – Understanding, Preparing, and Troubleshooting Dynamic Apps on AWS (ARC303)
Speaker: Lee Atchison, Principal Cloud Architect, New Relic
Track: Architecture
Level: Advanced
When: Wednesday, Nov 30, 2:00 PM – 3:00 PM
Why we like this session: Cloud monitoring has become a huge challenge with the advent of more and more dynamic services. New Relic offer an interesting solution for resource utilization monitoring, and as a company offering tools for cloud monitoring ourselves, we’d love to hear about New Relic’s experience in this field.
Abstract: “Applications running in a typical data center are static entities. Dynamic scaling and resource allocation are the norm in AWS. Technologies such as Amazon EC2, Docker, AWS Lambda, and Auto Scaling make tracking resources and resource utilization a challenge. The days of static server monitoring are over.
In this session, we examine trends we’ve observed across thousands of customers using dynamic resource allocation and discuss why dynamic infrastructure fundamentally changes your monitoring strategy. We discuss some of the best practices we’ve learned by working with New Relic customers to build, manage, and troubleshoot applications and dynamic cloud services.”
Some Final Tips
Some sessions are expected to be completely full. You can reserve a seat, so be sure to visit the conference site and reserve your seat as early as possible.
You do not want to miss any activity with the GA prefix — these include the welcome reception, keynote, pub crawls, and other special events.
If you find the time, you might also want to make yourself available for some of the partner theater sessions (PTS). These are short and light engagements in which selected AWS partners show off their wares.
Be sure to rest up between sessions. re:Invent can be a tiring event, so we recommend taking breaks and consuming plenty of liquid (and not the alcoholic kind).
Meet Logz.io at AWS re:Invent
Logz.io is a Silver sponsor of re:Invent, and we will be on the floor at Booth #1019. So, in between sessions, be sure to pay us a visit and learn all about our log analysis platform that offers the open source ELK Stack as a cloud service powered by artificial intelligence. You can reserve a demo slot by clicking here OR here if you’re interested.
Daniel Berman is Product Evangelist at Logz.io. He is passionate about log analytics, big data, cloud, and family and loves running, Liverpool FC, and writing about disruptive tech stuff.